
What is Machine Learning?
13th August, 2018
There is often is a lot of confusion surrounding the term ‘Machine Learning’. To clear it up, we asked one of our Machine Learning experts to define the term for us. Here is a succinct overview of the fundamentals of Machine Learning and a run-down of the solutions available within the subject area.
Machine: is not a machine like the one you see in the movies that provides fancy and virtual technical solutions, nor can your laptop or PC be classified as a machine. In fact, a machine is something you cannot even see or touch. Machine is simply an algorithm, developed by mathematicians before World War 2 (yes, you read that correctly World War 2!), that you select from a software, and that yields results when you click the button, Run! It is as simple as that!
Learning: The term learning has nothing to do with the learning methods we experienced at school or university, or like any learning skills that can be gained at trainings. Instead, learning is the algorithm that YOU PERSONALLY select, that runs its codes to find the optimized model as the best solution for your request based on the data uploaded. If you’re somehow not convinced, let's go back 20 years. When running Logistic regressions, Principle Component Analysis, SVMs, or even Neural Networks, what did they use to name such an act at that time?! Analysts simply used the term ‘learning’ to tell each other to "run the algorithm", and over the years it became known as "Machine Learning". It’s just a buzz word guys!
There are three categories within Machine Learning:
- Unsupervised
- Supervised (predictive)
- Reinforcement
I will explain Unsupervised Machine Learning briefly, before going into detail about Supervised Machine Learning. (If you are interested in learning more about Supervised Machine Learning it will be taught as a complete Machine Learning and Predictive models workshop by Meirc Training and Consulting. To learn more about the program, please click here).
1. Unsupervised Machine Learning:
Finds hidden patterns that reside in your data to draw inferences about the data. These include, relations between different behaviors or opinions (PCA), similarities between observations (clustering) or associations between classes (Simple Correspondence Analysis).
2. Supervised Machine Learning:
Makes predictions based on the data provided. The word supervised means that you want to predict the unknown class or value of a variable labeled Y based on the known Xs, that are labeled as predictors. Now if Y is categorical like Gender (Male or Female) or Sentiment (Good or Bad), we are in the classification mode. But if Y is a numerical variable, such as sales or KPIs, we are in the estimation mode of Y!
I will now briefly explain about the most important Supervised Machine Learning algorithms. All Supervised Machine Learning models have the same objective and role: classify or estimate Y based on the information available on the Xs. Imagine you are a banker and want to know if you should give your customer a loan or not. You can do so by simply asking the customer on the different financial criteria, the (Xs), input this information into the computer, and then wait for the computer to determine whether to lend the loan or not (Y). To obtain the answer for your question on whether to give the loan or not, you simply have to click the button Run! But Run of which model?! OF THE ALGORITHM SELECTED BY YOURSELF and NOT THE COMPUTER! The computer only executes your commands.
Now to get this model, or “teach” the machine (algorithm) what to deliver as an output, you have to feed it with historical data upon which it can learn (optimize the solution) or let’s use a fuzzy word, “train” itself to find that best fit model.
As you can tell, it is up to Human Learning capacities to select which Supervised Machine Learning model is best for the uploaded data. Below is a list of Supervised Machine Learning models that are used within different software packages in the market:
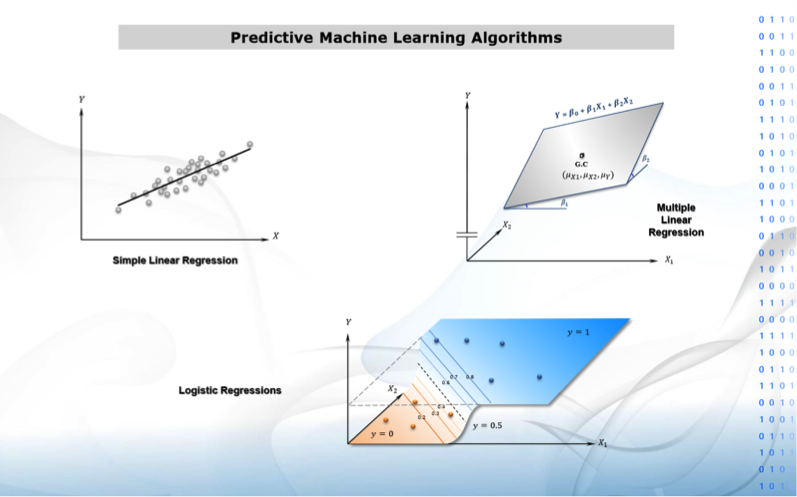
1. Regression models: estimates Y knowing Xs via simple linear models.
2. Logistic regression: classifies Y knowing Xs via simple exponential models.
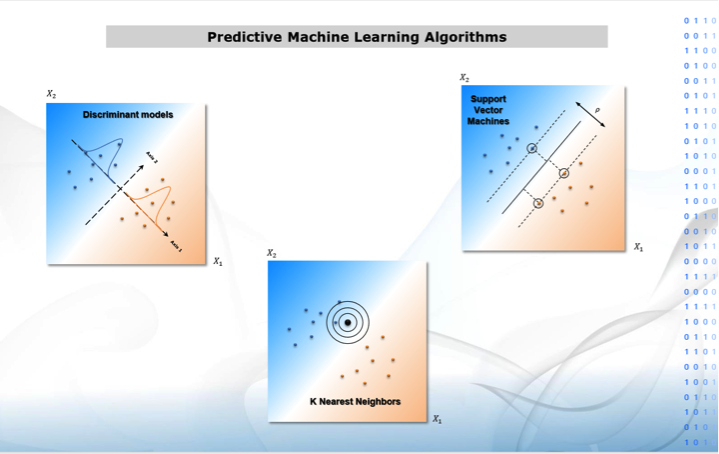
3. Discriminant Analysis: classifies Y knowing Xs via new hybrid models.
4. K Nearest Neighbors: classifies Y by finding closest similar observations on Xs.
5. Naïve Bayes: classifies Y by finding highest probabilities generated from Xs.
SVMs: classifies or estimates Y by plotting identical observations into specific areas which boundaries are calculated linearly from Xs.
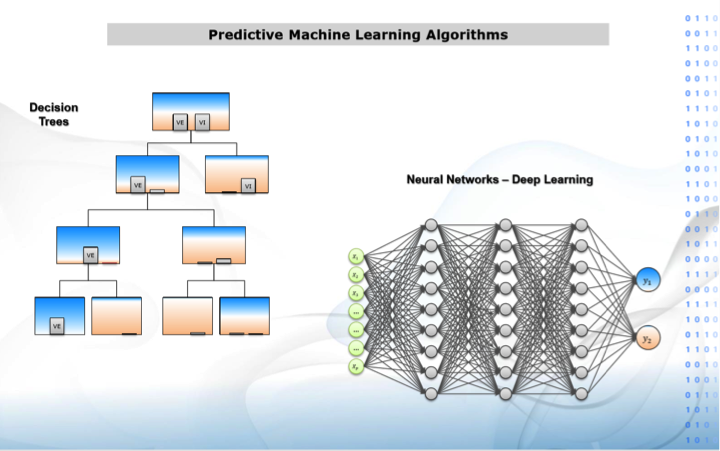
7. Decision Trees: classifies or estimate Y by separating observations via Xs.
Neural Networks: classifies or estimates Y from Xs by finding out weights relating neurons!.
I am sure you are probably wondering by now on which the best Supervised Machine Learning model is and what technology to use? It is like asking what would be the best car to drive on a Saturday night (although a Ferrari isn’t a bad choice at all). Technologies range from the luxurious SAS technologies (priced like a Ferrari), down to STATISTICA or even open sources such as R and Python (free of charge). And for the best Supervised Machine Learning model, each has its pros and cons. However, your best approach would be to apply the 8 models, compare their results, and find out which one can be your best most humble servant. Why humble? Because it is frequently more judicious to select a less sophisticated model that can be understood by your colleagues and upper management and easily implemented in your company, rather than a more complicated one which will generate little better precision in your predictions!
About the Author
Related Blogs

Digital Imperative: Transformative Investments in Information Systems
In today's fast-paced business environment, possessing cutting-edge information systems isn't just a competitive edge; it's a strategic imperative. Across the globe, governments recognize the pivotal role of i...
Karim Salem, PMP®, PMI-ACP®
14th February, 2024
Read More

The Impact of company culture on Digital Transformation
Company culture is a term that is often heard when advertising a business to prospective employees, however, the implications of culture run deeper than the perks of a job. As we move towards a world that ada...
Facilitator/ Blogger
11th November, 2019
Read More